
Paper Review : BertSumExt (2)
이전 포스트에서 BertSumExt 의 전체적인 모습을 살펴보았다면, 이번 포스트부터는 BertSumExt 에서 가장 중요한 (거의 전부인..) 부분인 TransformerInterEncoder 에 대해 적어볼 것이다. 먼저, BertSumExt를 도식화 했던 것에서 TransformerInterEncoder 부분만 확대해보면 다음과 같다.
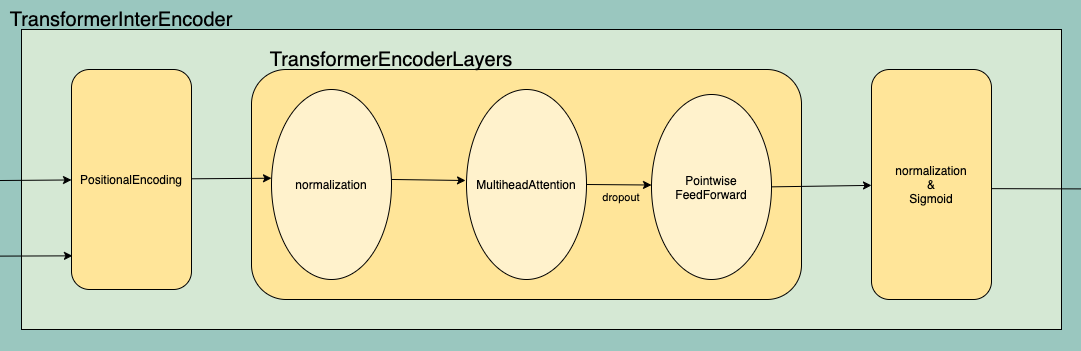
오늘은 TransformerInterEncoder 부분을 구성하고 있는 PositionalEncoding 과 TransformerEncoderLayers 를 간단히 살펴보자.
1. Positional Encoding
PositionalEncoding 부분은 BERT 의 output 을 가져와서 sentence 들의 position을 더해주는 작업을 해준다고 한다. PositionalEncoding 부분만 살펴보자.
class PositionalEncoding(nn.Module):
def __init__(self, dropout, dim, max_len=5000):
pe = torch.zeros(max_len, dim)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp((torch.arange(0, dim, 2, dtype=torch.float) * -(math.log(10000.0) / dim)))
pe[:, 0::2] = torch.sin(position.float() * div_term)
pe[:, 1::2] = torch.cos(position.float() * div_term)
pe = pe.unsqueeze(0)
super(PositionalEncoding, self).__init__()
self.register_buffer('pe', pe)
self.dropout = nn.Dropout(p=dropout)
self.dim = dim
def forward(self, emb, step=None):
emb = emb * math.sqrt(self.dim)
if (step):
emb = emb + self.pe[:, step][:, None, :]
else:
emb = emb + self.pe[:, :emb.size(1)]
emb = self.dropout(emb)
return emb
def get_emb(self, emb):
return self.pe[:, :emb.size(1)]
TransformerInterEncoder 의 코드를 살펴보면 위 코드에서 dim 자리에 d_model 이 들어가는데, d_model 에는 bert.model.config.hidden_size 가 들어간다. 이를 $n_h$ 라고 하자. 그리고 max_len 은 디폴트로 5000이 박혀있긴 하지만 그냥 적당히 큰 값 $N$ 이라고 하자. 그러면 PositionalEncoding 에서 더해주는 position 값은 아래와 같이 계산된다. (꼴에 통계학과라고 코드보단 수식이 익숙하다)
Let $pe$ be a matrix as follows.
\[\begin{aligned} pe = \begin{bmatrix} x_{00} & x_{01} & \cdots & x_{0n_h} \\ x_{10} & x_{11} & \cdots & x_{1n_h} \\ \vdots & \vdots & \ddots & \vdots \\ x_{N0} & x_{N1} & \cdots & x_{Nn_h} \end{bmatrix} \end{aligned}\]For $x_{ij}$ where $i = 0,1,2,\cdots,N$ and $j = 0,1,2,\cdots,n_h$,
\[\begin{aligned} x_{ij} = \begin{cases} \sin \left[ i \cdot (-j \cdot \frac{\log(10000)}{n_h}) \right] \quad \text{if j is even} \\ \cos \left[i \cdot (-(j-1) \cdot \frac{\log(10000)}{n_h}) \right] \quad \text{if j is odd} \end{cases} \end{aligned}\]이러한 수식은 Attention Is All You Need 의 3.4 Positional Encoding 에서 확인할 수 있다. 이 논문에서 이와 같은 sinusoid function 을 채택한 이유는, 어떠한 fixed offset k 에 대해서 $x_{pos+k}$ 가 $x_{pos}$ 의 선형 함수로 표현될 수 있기 때문에 모델이 상대적인 position 에 대해 attend 하도록 학습 가능할 것이라고 가정했기 때문이라고 한다. 원 논문에서는 words 간 relative position 을 encoding 했다면, BertSum 에서는 sentence 간 relative position 을 encoding 한다는 차이점(혹은 추가된 점)이 있겠다.
이 부분 때문에 어쩌다보니 Convolutional Sequence to Sequence Learning 이라는 논문도 살짝 읽어보게 되었다. Attention Is All You Need 에서는, 현재 사용하고 있는 sinusoid 와 이 논문에서 나오는 learned positional embeddings 와의 성능 차이도 비교해보았고 거의 똑같은 결과가 나온다는 것을 확인하였다고 한다.
TransformerInterEncoder 에서 forward 함수를 보면, top_vecs 에 mask 를 씌운 뒤 이렇게 만든 positional encoding 을 더해주었음을 알 수 있다. 이렇게 Positional Encoding 이 된 벡터들은 여러개의 TransformerEncoderLayer 로 이루어진 Module list 를 지나게 된다.
2. Transformer Encoder
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, heads, d_ff, dropout):
super(TransformerEncoderLayer, self).__init__()
self.self_attn = MultiHeadedAttention(
heads, d_model, dropout=dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, iter, query, inputs, mask):
if (iter != 0):
input_norm = self.layer_norm(inputs)
else:
input_norm = inputs
mask = mask.unsqueeze(1)
context = self.self_attn(input_norm, input_norm, input_norm,
mask=mask)
out = self.dropout(context) + inputs
return self.feed_forward(out)
이 레이어 자체는 단순하다. input이 LayerNorm 을 지난 뒤, MultiHeadedAttention 을 지나 dropout 시킨 것을 다시 input 에 더하고 PositionwiseFeedForward 에 넣는 거다. 이 과정을 TransformerInterEncoder 의 forward 함수에서 인간지네처럼 계속 계속 하면 된다(ModuleList).
3. 다음 포스트 계획
이제는 BertSum 만의 알고리즘에 대한 내용은 끝났다. 다음 포스트에서는 TransformerEncoderLayer 를 구성하는 MultiHeadedAttention 과 PositionwiseFeedForward 에 대해 알아보자. 사실 이 내용은 BertSum 자체의 내용이 아니라 Transformer 에 대한 내용이다. BertSum source code 중에서는 neural.py 에서 확인할 수 있다.
다시 첨부하는 링크들 :
Leave a comment