
Paper Review : BertSumExt (1)
요새 NLP 에 관심을 가지다가 Text Summarization 이 생각보다 다른 분야에 비해 어렵다! 라는 생각이 들었고, 어려우니까 왠지 궁금해졌고… 해서 살짝… 공부해보게 되었다. 그 중, BertSum 과 MatchSum 에 대해 읽게 되었고, 이번 포스트에서는 BertSum, 그 중에서도 BertSumExt 에 대해 간단히 소개해보도록 하겠다. 물론 나는 엄청난 뉴비이기 때문에 그냥 이해한 부분만 쓸 것이다(…) 뇌피셜 다수 있으므로 제발 댓글로 지적 좀 해주세요 ㅠㅠ
1. Text Summarization 에 대해서
Text Summarization 에는 두 가지 종류가 있다.
-
Extractive (추출요약)
-
Abstractive (생성요약)
비록 두개 다 요약의 문제이긴 하지만, 모델링의 입장에서는 둘은 아예 다른 task 인 것 같다고 생각했다.
1.1 Extractive Summarization
추출요약이란, 문서에서 가장 중요한 문장 n 개를 추출하는 방식이다. 그래서 문장 별 Binary Classification task 라고 할 수 있다. Sentence Generation 이 필요하지 않기 때문에 후술할 Abstractive Summarization 보다 간단한 task이다. 간단한 예시로 이런 글이 있다고 생각해보자.
나는 내가 예쁘다고 생각한다. 이유는 다음과 같다. 먼저, 거울을 보면 기분이 좋다. 두번째, 사람들이 자꾸 말을 걸어준다. 마지막으로, 내가 그렇게 생각하기 때문이다. 반박은 받지 않도록 할 것이다.
문장의 개수는 총 6개이다. 따라서 extractive summarization 을 위해 각 문장에 라벨링을 한다면
[1, 0, 0, 0, 0, 1]
처럼 할 수 있을 것이고, 요약된 글은
나는 내가 예쁘다고 생각한다. 반박은 받지 않도록 할 것이다.
가 된다.
1.2 Abstractive Summarization
생성요약이란, 정말 우리가 생각하는 요약이다. 중요한 정보를 캐치해서 문장을 만들어 내야하는 것이다. 따라서 Classification이 아니라 Sequence to Sequence problem 이라고 본다. 앞서 든 예시를 abstractive summarization 해본다면
나는 내가 3가지 이유로 예쁘다고 생각하며 반박은 받지 않는다.
가 된다. 솔직히 말하면 이게 잘 될까… 하는 회의적인 마음이 들어서.. 일단은 Extractive summarization 에 집중해보기로 했다. 평소에 classification task 를 많이 해보기도 했고.
2. BertSumExt
논문 링크와 깃헙 링크 먼저 첨부한다.
2.1 Text Classification using BERT
여기서부터 시작하는게 좀 더 이해가 빨랐던 것 같다. 가장 간단한 Text Classification task 를 생각해보면 다음의 예시와 같을 것이다. (긍정=1, 부정=0)
| Index | Text | Label |
|---|---|---|
| 0 | 여기 진짜 개 맛없음 쓰레기같은 음식 | 0 |
| 1 | 맛있네요. 재주문 2번째입니다! | 1 |
| 2 | 그냥 뭐… 좀 짰습니다. | 0 |
| 3 | 배달이 왜 이렇게 느려요? ㅡㅡ | 0 |
| 4 | 저희 아이가 좋아했습니다. | 1 |
Supervised Learning 의 경우 내가 참고한 포스트는 김영근님이 medium에 작성하신 Bert를 활용한 감정분류 by Pytorch 이다. 다른 예시들과 달리 BertForSequenceClassification 을 사용하지 않고 BertModel.from_pretrained('bert-base-uncased') 을 가져와서 모델을 만들었다. 이진분류문제라면 전자를 가져와서 해도 되겠지만 나중에 multilabel 등의 task에도 적용하기 위해서는 후자의 방식이 좋을 것이다.(내가 이해한게 맞다면 말이지) 아무튼 복잡한 설명 다 제외하고 김영근님의 코드를 단순히 도식화해보면 아래와 같다. n 개의 token 을 가진 문장 한개를 bert classification model 에 넣었을 때, 다음과 같은 절차를 거쳐 결과물이 나온다.

주의할 점은, category 개수만큼의 결과물이 나온다는 점이다. 이진 분류 문제의 경우 문장 하나 당 두 개의 숫자가 나오는데, 이를 score 이라고 생각하면 된다. 따라서 np.where(output==max(output)) 를 실질적인 라벨값으로 생각해주면 되겠다.
이것을 Extractive Summarization 으로 확장한다면, 이제 classification에 더하여 문장 간의 관계도 생각해주는 모델이 필요하다…!
2.2 Bert + Transformer Model
모델 부분만 뜯어보면 다음과 같이 그려볼 수 있다. 표기는 깃헙의 코드 (src/train.py부터 시작해서 레퍼런스 타고 올라가는 식으로 보았다.) 를 참고했다.
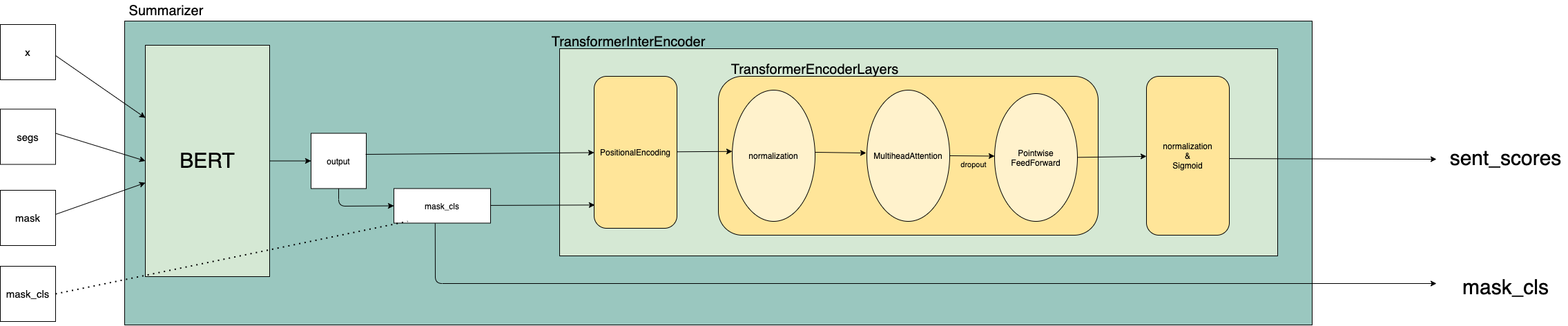
-
여기서
mask_cls의 generation은 data_loader.py 내의class Batch(object)에서 확인할 수 있다.pre_clss는 input 중 clss 를 의미한다. -
TransformerEncoderLayer은
ModuleList를 이용하여 여러 개가 연결되어 있으며, input은 ModuleList를 차례로 지난다. 인간지네 생각하면 편하다.
clss = torch.tensor(self._pad(pre_clss, -1))
mask_cls = 1 - (clss == -1)
자세한 사항은 차례대로 다음 포스트에 쓰도록 하겠다.
3. 다음 포스트 계획
모델에 쓰인 TransformerInterEncoder 에 대해서 더 자세히 알아보도록 하자. 흐에엥 힘들어..
Leave a comment